

Pricing heuristics
If you’re an early-stage founder and you’re not charging for money for a product that you intend to eventually charge money for, you should start doing it, now. That’s because the best way to tell whether you’ll be able to charge money tomorrow is to see if you can successfully charge money today.
If early customers refuse to pay for your product then you have a strong signal that you need to change something with your approach. Many founders avoid this at first because it’s uncomfortable and because it’s a big hairy problem. It’s so abstract that it’s partly philosophical.
That’s why there’s almost as many theories of pricing around as there are entrepreneurs. In my opinion, the best way to approach a hairy, abstract problem like this is to simplify it by using a heuristics, or rules of thumb, as a starting point.
Below are a few common heuristics that worked for me at Firefly.
While none of these are particularly ground-breaking, I hope it’s useful to see them all in one place and explained for early-stage founders (instead of MBAs).
Heuristic #1: Value-based
If what you’re doing really hasn’t been done before (much less common than most entrepreneurs think) and there aren’t any comparable products for you to base your price on, then a good model is called value-based pricing. It works like this: estimate the amount of value your product brings to a customer, and then charge some small percentage of that.
In practice, this is much more difficult than it seems because in most cases you have no idea how much value you bring to a customer. So you start with a bunch of assumptions – and depending on whether you think you should charge a lot or a little you fit your assumptions to your preference – and boom out comes the number that you wanted all along.
But this approach has the advantage of forcing you to make your assumptions explicit so that later on you can modify the price as you falsify or change them.
Heuristic #2: Cost-plus
You can look at how much it will cost you to build and support your product and charge some multiple on that. Generally the cost in cost-plus is referring to unit cost – the cost to produce one unit of a product. However, because many software companies have very low unit costs, this heuristic may not seem to apply to a lot of you.
However, sometimes adding a customer will increase the overhead required to run the business. In this case, it can be good to incorporate the overhead costs into the cost-plus model when pricing to be sure that you won’t end up losing money by signing a new customer.
For example, at Firefly we were signing contracts that required us to support the product 24/7, so we looked at what it would cost us to hire enough people to do that support so that we could estimate whether the value of the contract made that worthwhile.
We didn’t end up hiring 24/7 support people, we just always had our cell phones turned on and under our pillows, but it was a good exercise nonetheless.
So, for software, cost-plus can be a good defensive pricing strategy, or a good way to set your floor.
Heuristic #3: Look at your competitors
What are your competitors charging? This is often the best place to start because they already have much more information than you. Map out every offering and its price. Then either go higher if you’re trying to create a premium product, or go lower if you’re trying to provide the same value at a lower price.
Even if a competitor doesn’t do exactly what you do, it’s still a useful barometer. For example, when we were starting Firefly and were doing pricing for the first time, we looked at other co-browsing companies but because there weren’t many out there we also looked at screen sharing companies.
This allowed us to come to market with a price that was reasonable, that we could get in the door with and justify.
Then we modified it from there.
28 Sep 2016, 11:23am | 1 comment
Would I do this for 10 years?
Let me tell you something I believe that I think most people in tech don’t:
If you’re a young entrepreneur just starting out, asking yourself “Would I do this for the next 10 years?”, as a way to figure out whether or not you should be working on something, is, in my opinion, totally unhelpful.
This isn’t because I’m advocating against a long term approach. I think it’s great to work on something for a long time.
Rather, I think it’s a bad question because we’re just not good enough at predicting our desires over the long term to be able to answer it. We’re capricious animals. We’re generally fickle and impulsive. We’re maddeningly mercurial.
Mostly this advice is given by 50-year old investors to 20-year old founders as a way to figure out what they should work on. But I think it misses something important: when you’ve never worked on anything for more than a couple of months, you don’t have the tools to judge whether your answer to this question is reflective of temporary enthusiasm or something more lasting.
I’ve seen this first hand. I can’t tell you how many of my friends have come to me at some point or another and say things like, “I feel like I’ve found it! Supply chain management is what I want to spend the next 10 years on!”
With a few exceptions, they’ve almost always moved on to something else within a couple of months.
Most pressingly, when you’re just starting out, I think asking yourself that question can be actively harmful because it sets the bar too high. If you’re constantly asking yourself, “Would I do this for 10 years?” for something you’ve just started, the answer is more likely than not to be “No” at a few points along the way — given the extreme ups and downs involved in starting a company.
When you ask yourself that question, you’re focusing on surface-level results which tend to fluctuate randomly early on. Some days you’ll be on top of the world, and some days you’ll be down in the dumps. It’s a bad habit to draw long term conclusions (like whether you should be working on this long term) from short term results. It will make it much harder to manage your psychology.
Instead, it’s more helpful to ask yourself questions whose answers don’t depend so entirely on how things have been going that day. For me, the most helpful one was this:
Am I learning? Importantly, am I learning what I want to learn?
If the answer was yes — and at Firefly the answer was mostly yes — it gave me the stamina to keep working even when things didn’t seem to be going my way. And that can make all the difference.
20 Sep 2016, 1:41am | 7 comments
One good trick for interviewing candidates at a small startup
At the beginning of every interview I always ask one question, and it almost always separates the high-quality, serious candidates from the people that are just curious or are used to skating through interviews. The first question I ask is:
So can you pitch me what our company does?
And it’s always 100% clear which candidates have spent time doing their research and thinking about our product and which ones have just shown up hoping to wing it.
This isn’t as useful for a really well-known company, but if you’re a small startup it’s wonderful.
And the best part is that I’m not giving up any secret that will make this less likely to work in the future. The only people who will read this are the ones that already do research anyway.
8 Sep 2016, 4:14pm | 3 comments
Should I OEM my product?
I was sitting on my roommate’s dilapidated couch in West Philadelphia when the contract came in:
$4,000 a month with significant room to grow.
There was a squiggle at the bottom of its 15 pages indicating that a real live person working at a real live company had committed to pay us that much money every month for some software we had written.
I checked everything through to make sure this wasn’t a joke. Then I screamed my head off with joy. This was it – we were finally a real business.
We had launched Firefly approximately 11 months prior, and until then had been scraping along with about $1,500 a month or so in revenue from a few small customers. For a bootstrapped startup run by just two college age kids this latest contract represented a giant step up in our revenue graph, and by extension our prospects. We could now run the business indefinitely – and maybe even hire someone to help us out part time.
This moment validated a somewhat unusual strategy we had decided to pursue some months prior. We had started out the company selling directly to the customers that were going to use our product. But over time we had shifted strategies, and this deal was the first fruit of that shift. Instead of selling directly to customers, we decided to build our product into an API, and allow other companies to build it into their products, and sell it to end-customers for us.
How we got to the API strategy
We had this technology we had built called co-browsing. Basically, it works like screen sharing, but instead of sharing your screen you share just a web page. It doesn’t require any downloads or installations to run, and it works across platforms (Mac, PC, iPhone, iPad and Android).
After some playing around we decided to focus primarily on a customer service use case: when a customer is having a problem with a website, we allow the agent to look over their shoulder and help them through the site in real time.
And we had been trying to sell it with some success, but we weren’t blowing it out of the water. What we found was this: small companies wanted it but couldn’t pay too much for it. Big businesses, on the other hand, moved really slowly, looked at it as a feature rather than a product, and were hesitant to work with a company as small as ours.
Becoming an API company solved our distribution problem in one fell swoop: by allowing other companies to sell us to their customers we could launch to thousands of SMBs without having to go through the pain of signing them up individually and we could be sold to large businesses through their existing vendors (thus eliminating their worries about our size and whether what we were selling was a feature or a product).
Over time we did more of these deals, and evolved our vision for what the company could be based on what we saw. Instead of just being a co-browsing company, we looked at ourselves as something like a Twilio for co-browsing. We provided an API that allowed any company to build this feature into their product and sell it to their customers.
If you have a product that works well as a feature of a larger platform, becoming an API company and selling your product through OEM relationships can look like a very appealing path. As someone who’s walked it, I want to go through the pros and cons of running this type of business so you can decide whether it’s right for you.
Different types of API businesses
Before we get started, it’s important to note that not every API company is an OEM business. In fact, the percentage of API companies that pursue OEM as a strategy is probably relatively small.
This piece is going to focus on the OEM strategy specifically – that’s where much of our business at Firefly came from – but some of this applies to other types of API businesses.
Let’s start with the benefits of pursuing a strategy like this.
Instant distribution
When you do an OEM deal with another company that already has a large customer base, it’s a great way to scale up your operation (in terms of customers and revenue) quickly. For example, one of the first OEM deals we did was with a live chat company called Olark. When the deal closed we went from being used a few times a day by a couple of SMBs to being deployed to (at the time) about 5,000 SMBs – a number which grew reliably every month.
It also can give you access to companies that wouldn’t ordinarily give you the time of day. For example, shortly after launching with Olark we did another deal with a large customer service company that bundled us into their product and sold us to Best Buy – a company that would have been difficult or impossible for us to sell to on our own given our size and lack of funding.
Great acquisition target
Doing OEM work makes you a very attractive acquisition target for the right type of business.
For one thing, your partners become natural acquirers: they know your product works, they have a need for it because they’re selling it to their customers, and you’re already integrated into their platform.
But more generally, because you’ve built your product to integrate seamlessly into anyone else’s platform you’ve taken one of the big risks / pain points of most acquisitions – integration – and made it into a non-issue. This makes you a much more attractive buy than if you had a product that would have to be totally shut down and rebuilt to integrate into the existing platform.
Indeed, when senior execs at Pega were initially looking to buy Firefly they were stunned that it took only a few minutes to integrate our co-browse into their flagship CRM product Pega Customer Service. That made a big difference in the deal.
Guaranteed revenue, low cost
Finally, the upside of doing these types of deals and getting instant distribution is that you can generally translate that pretty easily into revenue. When we closed our first OEM deal we went from about $1,500 a month in revenue to over $5,000 a month. And within less than a year we had almost 10x’d that number. And we were still just 2 full time founders with a couple of contractors helping us out part time.
To get to that kind of a revenue number without doing OEM deals we would have had to expand our headcount dramatically above where we did. For example, because we were selling to businesses almost all of our contracts had stringent SLA requirements for both server uptime and customer service response time.
Doing support for thousands of businesses, and ensuring that we had a 24/7 operation would have been pretty much impossible with just two co-founders and a few part-time hires. But because we were OEMing our product, the businesses we were selling to were responsible for the first level of customer service when anything went wrong.
Because our customers acted as a filter for their customers, this allowed us to get away with not scaling up our support operation. Instead, we hooked our “24/7” support line up to our cell phones and never slept without our phones under our pillows. We had a few late-night emergencies, but not nearly as many as if we had been doing first line support.
To recap: doing OEM deals allowed us to build a significant base of monthly recurring revenue at a very low cost. This is really important if you’re bootstrapping.
The darker side of OEM
As beneficial as becoming an OEM can be, there are also significant issues involved in running an API-based OEM business that can dramatically limit your growth potential. Let’s discuss those.
Serving multiple constituencies
When you run an API-based OEM business you have to serve two constituencies: your customer, and the end-customer (your customer’s customer.)
Serving multiple constituencies hurts as a startup for a few reasons. First, because you have limited resources it can be hard to spend enough time optimizing your product for what the end customer wants and what your integration partners want. It’s not impossible to do, but it results in a less focused, sometimes lower quality product for each of the constituencies you’re serving.
Second, sometimes the needs of your constituencies are opposed. For example, the end customers may want you to implement a feature that competes with one of your OEM partners. If you built it, you’d make them happy, but you’d be putting your business at risk.
You don’t own the customer relationship
When you go the OEM route you don’t own the end-customer relationship. This is an issue for a few reasons:
First, your business is less valuable if you don’t own the customer relationship. Any potential acquirer is going to look at your list of customers as a way to value your business. If all of your end customers are actually owned by someone else, it makes your revenue stream less valuable.
Second, when you don’t own the customer relationship information flow becomes a huge problem. This isn’t so obvious before you try to run one of these businesses, but becomes a big pain once you’re in the middle of it.
What we wanted to do was build the best co-browsing experience possible for end-customers. But we didn’t have access to those end customers (aside from during support calls) even though there were thousands of them. We had to go through our partners to find out what was happening with the product, what should be improved, and where we could expand.
For example, using a product like Intercom, or Feedbackify, most startups are able to talk directly to their end-users or gather survey data from them as they’re using your app. Because we didn’t technically own the customer relationship we couldn’t just add a little chat widget into the co-browse experience. Our partners wanted a branded, seamless, and streamlined co-browse experience, not one that included surveys or chats with us. So doing something like this to gather feedback was a no-go.
This extra friction makes it hard to move as quickly as you need to – which often spells death for a small startup and can result in a lower quality end product.
Perverse incentives for word of mouth
With a regular company, if your product works really well, the people that buy it will tell their friends and your business will naturally grow via word of mouth. OEM businesses don’t really work this way because a company that is OEMing you is naturally incentivized to keep it as quiet as possible by white labeling you and not tipping their competitors off to the fact that you’re providing this feature for them.
Think of it this way, if a company considers it a competitive advantage to have your product incorporated into theirs, what is their natural incentive to share that knowledge with their competitors? They have none, and so the task of signing up more OEM customers is that much more difficult.
Beyond not owning the customer relationship, serving multiple constituencies, and encountering perverse incentives, there’s one other major difficulty in selling an API-based OEM product. I call it walking the strange line.
Walking the strange line
This is the big issue that we ran into time and time again in our sales cycle and limited our growth more than anything else. When you’re selling an API solution to a company that wants to integrate it into their product and sell it to their customers you have to walk a line:
You have to simultaneously convince them that it’s not core enough to their business for them to build themselves, but you also have to convince them that it’s still important enough for them to pay you lots of money to provide to them.
These are two conflicting notions for a customer. If something isn’t core to their business, why bother to buy it and build it into their product? If something is core to their business, shouldn’t they own it?
You’ll run into this often when building an API-based OEM business. And unfortunately, whether or not you can manage the objection has more to do with the type of product you have than it does with the answer you give.
The key to a successful OEM business
The only way around the strange line problem is this:
You have to have a product that is important to their business, but that they don’t have the expertise to provide effectively themselves.
The best example I can think of for this is Windows – although it’s not an API it is the classic software OEM play.
We struggled with this a bit because most of these companies could build our co-browse product themselves (building client-side heavy, realtime software was a core competency) but what we were doing was difficult enough for them to shy away from doing so in many cases.
The best way to think about this is as a graph. On the X-axis is how different what you’re doing is from your partner. On the Y-axis is how much demand there is for the feature you provide. If you’re in a quadrant where what you’re doing is significantly different from their core, and there’s demand for the feature you enable, you’re in the clear:
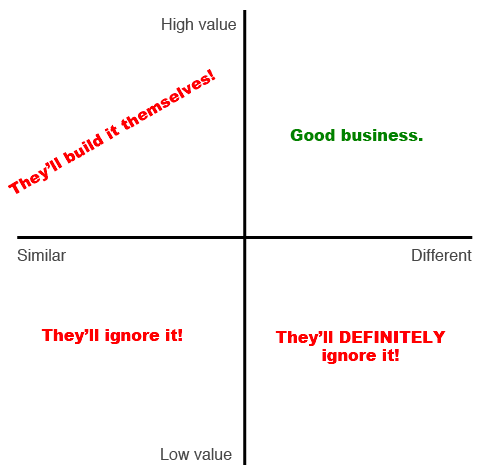
Otherwise, think twice about whether pursuing an API-based OEM strategy is right for you.
Final thoughts
So let’s say you’re in the top right quadrant of the graph above. Should you pursue an OEM strategy?
If you’re running a venture backed software company my recommendation would be to avoid doing OEM deals – a recommendation that you’ll likely hear from your VCs. This is because you’ll likely encounter problems that will hamper your growth like perverse incentives, multiple constituencies, and the strange line problem.
However, if you’re running a bootstrapped company like we were, doing OEM deals can be a huge boon to your business. You’ll be able to scale up quickly with minimal overhead and get your revenue number to a point where you have a self-sustaining business.
We bootstrapped our business to almost a half a million dollars a year in recurring revenue in about 2 years with two co-founders and 3 part-time contractors before we sold it to Pega – a publicly traded enterprise software company – in 2014. If we hadn’t pursued an OEM strategy, we would not have been able to sniff the revenue numbers we hit in the time period we did without raising money and significantly scaling up our operation.
Thanks to Miles Grimshaw and Ryan Dawidjan for reading drafts of this.
6 Sep 2016, 12:18am | leave a comment
Building a Better Train to Brooklyn
Rosanna lives in Brooklyn so I take the train a lot.
More specifically, I take the 6 train to Union Square. Then at Union Square I transfer to the L train which brings me from Manhattan to Brooklyn.
A few days ago I was walking to catch L when I started thinking: how could I build a better train to Brooklyn?
As you might imagine, this isn’t a simple question to answer. The problem is huge. You’re not just designing trains – you’re designing stations, signage, schedules – a whole system. I don’t even know much about trains – it seems like I couldn’t get very far.
If I wanted to design a better train I might do something like the following:
First I would think about the trains that I take every day. I would think about all of their features and start writing them down because I would probably need those features in my train as well.
I’d write down the name of the train. The way its logo looks. I’d write down how its seats look, and maybe estimate how many passengers could fit in each car. I’d think about what the railings will look like for people to hang on to when they’re standing on a crowded train.
After copying the basics I might add a few new features – twists on the traditional train concept that will make my train different: What about if, instead of sliding out, the doors, like, slid up when they opened? Kind of like one of those DeLoreans. These will be my key differentiators from other trains out there on the market.
Then I’d start sending out emails with phrases like, “Groundbreaking,” “Innovative,” “Dent in the universe,” and my personal favorite, “All I need is to find someone to build it for me.”
I know this is a tempting way to go about it because I have done this. And I’d be willing to bet most anyone who has ever tried to build a product has done it too.
The problem is: it doesn’t work. If you’re working alone you feel lost a lot. It feels like there’s a huge gulf between what you’re trying to accomplish and the tools you have to accomplish it.
If you’re working as part of a team you tend having long, heated arguments about which features to include that are mostly won by the person who’s most convincing – not the person who’s right.
So, obviously we need a better way to figure out questions like:
How do I decide which features to include in my product and which ones to leave out? How do I know if one of the new features I’ve come up with is a good idea?
That’s what I’m going to talk about in this blog post. What I want to do is explain exactly what’s wrong with the process I described above. Then I’m going to propose a better way of looking at things to make designing high quality products easier (but not easy.)
Then I’m actually going to show you how you might start building a better train to Brooklyn. Continue Reading
22 Feb 2015, 8:23pm | 16 comments
Charlie Munger On How To Build A $2 Trillion Startup

Imagine it’s January of 1884 in Atlanta, Georgia. Glotz, an affluent fellow citizen, has invited you to participate in a peculiar competition:
You and twenty others are invited to present a plan to start a business that will turn a $2 million investment into a business worth $2 trillion by the year 2034.
Glotz will personally give $2 million to the person who presents the most compelling pitch in exchange for half of the equity in the new venture. There are only a few stipulations:
- The new venture must exclusively sell beverages (specifically non-alcohol or “soft” beverages)
- For reasons unknown Glotz has decided that company must be named Coca-Cola
You have 15 minutes. What would you say in your pitch?
That’s the question that billionaire Coca-Cola investor Charlie Munger posed to an audience at a talk in July of 1996.
What followed over the following few minutes was an entrancing exhibition of multi-disciplinary wisdom and business acumen. Munger’s main point is that the most complex questions often have basic answers rooted in elementary academic wisdom (mathematics, psychology, etc.) He wants to show that applying some of these ideas regularly can help us to better explain business success, and make better decisions.
To start his talk, Munger lays out five principles he will use in his pitch to Glotz:
- Decide big no-brainer questions first
- Use math to help explain the world
- Think through problems in reverse
- The best wisdom is elementary academic wisdom
- Big (lollapalooza) results only come from a large combination of factors
Munger then dives in to solving the problem with his first principle: the big no-brainer questions that can be answered first.
“Well, Glotz, the big “no-brainer” decisions that, to simplify our problem, should be made first are as follows: First, we are never going to create something worth $2 trillion by selling some generic beverage. Therefore, we must make your name, “Coca-Cola,” into a strong, legally protected trademark. Second, we can get to $2 trillion only by starting in Atlanta, then succeeding in the rest of the United States, then rapidly succeeding with our new beverage all over the world. This will require developing a product having universal appeal because it harnesses powerful elemental forces. And the right place to find such powerful elemental forces is in the subject matter of elementary academic courses.”
Off the bat, it’s interesting to note how his prescription for growth largely mirrors the conventional startup wisdom espoused by Peter Thiel and others: grow quickly in a small market that you can dominate and then expand from there.
In the case of software, that market is typically a small niche of consumers. In the case of Coca-Cola (especially in the 1800s) it’s a small concentration of consumers in a geographically circumscribed area.
Next Munger moves on to his second and third principles: numerical fluency and thinking in reverse.
“We will next use numerical fluency to ascertain what our target implies. We can guess reasonably that by 2034 there will be about eight billion beverage consumers in the world. On average, each of these consumers will be much more prosperous in real terms than the average consumer of 1884. Each consumer is composed mostly of water and must ingest about sixty-four ounces of water per day. This is eight, eight-ounce servings. Thus, if our new beverage, and other imitative beverages in our new market, can flavor and otherwise improve only twenty-five percent of ingested water worldwide, and we can occupy half of the new world market, we can sell 2.92 trillion eight-ounce servings in 2034. And if we can then net four cents per serving, we will earn $117 billion. This will be enough, if our business is still growing at a good rate, to make it easily worth $2 trillion.”
Munger continues:
“A big question, of course, is whether four cents per serving is a reasonable profit target for 2034. And the answer is yes if we can create a beverage with strong universal appeal. One hundred fifty years is a long time. The dollar, like the Roman drachma, will almost surely suffer monetary depreciation. Concurrently, real purchasing power of the average beverage consumer in the world will go way up. His proclivity to inexpensively improve his experience while ingesting water will go up considerably faster. Meanwhile, as technology improves, the cost of our simple product, in units of constant purchasing power, will go down. All four factors will work together in favor of our four-cent-per-serving profit target. Worldwide beverage-purchasing power in dollars will probably multiply by a factor of at least forty over 150 years. Thinking in reverse, this makes our profit-per-serving target, under 1884 conditions, a mere on fortieth of four cents or one tenth of a cent per serving. This is an easy-to-exceed target as we start out if our new product has universal appeal.”
In this section, Munger demonstrates the value of the basic math involved in a TAM (total addressable market) analysis as part of formulating a thesis for a business. Then he goes on to look at the basic cost structure of the business and ensures that the back-of-the-envelope math makes sense for him to reach his ultimate goal.
As part of this analysis he makes a lot of forward looking predictions with the benefit of hindsight (the depreciation of the dollar, the real purchasing power of the average consumer, worldwide beverage purchasing power etc.) but for now we can ignore those issues.
Munger continues on to the meat of his talk: the subject of creating a product compelling enough to be consumed daily by millions of people. This is where he’s going to bring out his fourth and fifth principles: the value of academic wisdom, and the forces that must be brought together to produce “lollapalooza” effects.
“We must next solve the problem of invention to create universal appeal. There are two intertwined challenges of large scale: First, over 150 years, we must cause a new-beverage market to assimilate about one-fourth of the world’s water ingestion. Second, we must so operate that half the new market is ours while all of our competitors combined are left to share the remaining half. These results are lollapalooza results. Accordingly we must attack our problem by causing every favorable factor we can think of to work for us. Plainly, only a powerful combination of many factors is likely to cause the lollapalooza consequences we desire. Fortunately, the solution to these intertwined problems turns out to be fairly easy if one has stayed awake in all the freshman [college] courses.
Let us start by exploring the consequences of our simplifying “no-brainer” decision that we must rely on a strong trademark. This conclusion automatically leads to an understanding of the essence of our business in proper elementary academic terms. We can see from the introductory course in psychology that, in essence, we are going into the business of creating and maintaining conditioned reflexes. The “Coca-Cola” trade name and trade dress will act as the stimuli, and the purchase and ingestion of our beverage will be the desired responses.
And how does one create and maintain conditioned reflexes? Well, the psychology text gives two answers: (1) by operant conditioning and (2) by classical conditioning, often called Pavlovian conditioning to honor the great Russian scientist. And, since we want a lollapalooza result, we must use both conditioning techniques – and all we can invent to enhance effects from each technique.”
Let’s take some time to define a few of the things that Munger is talking about here so that it’s easy to follow the rest of the argument. Munger is mostly interested in the psychology of consumer decision-making: how can we influence consumers to buy a lot of a certain type of product?
There are two that he’s going to talk about here: operant conditioning and classical conditioning.
Classical conditioning is the method by which a strong innate response can become invoked by a neutral stimulus.
The most famous demonstration of classical conditioning is the work the Russian physiologist Ivan Pavlov did with dogs: he conditioned dogs to salivate at the sound of a bell.
To do this, every time Pavlov fed his dogs he would ring a bell. After repeating this procedure a few times, Pavlov found that he could ring his bell and the dogs would salivate without any food being present! (It’s historically questionable whether Pavlov actually used a bell, but we’ll leave it in for simplicity.)
Getting back to the subject at hand, it’s probably clear why this concept is so powerful: it means that it’s possible to trigger an innate biological response with a stimulus of your choice. Like, for example, a logo.
Now let’s briefly talk about operant conditioning. B. F. Skinner, the famed Harvard behaviorist describes operant conditioning in this way:
“When a bit of behavior is followed by a certain kind of consequence, it is more likely to occur again, and a consequence having this effect is called a reinforcer.”
In case this is confusing, Skinner elaborates with an example:
“Food, for example, is a reinforcer to a hungry organism; anything the organism does that is followed by the receipt of food is more likely to be done again whenever the organism is hungry.”
There is also a distinction between different types of reinforcers: some are negative and some are positive:
“Some stimuli are called negative reinforcers; any response which reduces the intensity of such a stimulus – or ends it – is more likely to be emitted when the stimulus recurs. Thus, if a person escapes from a hot sun when he moves under cover, he is more likely to move under cover when the sun is again hot. The reduction in temperature reinforces the behavior it is ‘contingent upon’ – that is, the behavior it follows. Operant conditioning also occurs when a person simply avoids a hot sun – when, roughly speaking, he escapes from the threat of a hot sun.”
Now that we have a little bit more background, let’s get back to Munger. Right now he’s trying to figure out how to use operant conditioning to increase the consumption of his product:
“The operant conditioning part of our problem is easy to solve. We need only (1) maximize rewards of our beverage’s ingestion and (2) minimize possibilities that desired reflexes, once created by us, will be extinguished through operant conditioning by proprietors of competing products.
For operant conditioning rewards, there are only a few categories we will find practical:
(1) Food value in calories or other inputs;
(2) Flavor, texture, and aroma acting as stimuli to consumption under neural preprogramming of man through Darwinian natutal selection;
(3) Stimulus, as by sugar or caffeine;
(4) Cooling effect when man is too hot or warming effect when man is too cool.
Wanting a lollapalooza result, we will naturally include rewards in all the categories.
To start out, it is easy to decide to design our beverage for consumption cold. There is much less opportunity, without ingesting beverage, to counteract excessive heat, compared with excessive cold. Moreover, with excessive heat, much liquid must be consumed, and the reverse is not true. It also easy to decide to include both sugar and caffeine. After all, tea, coffee, and lemonade are already widely consumed. And, it is also clear that we must be fanatic about determining, through trial and error, flavor and other characteristics that will maximize human pleasure while taking in the sugared water and caffeine we will provide. And, to counteract possibilities that desired operant-conditioned reflexes, once created by us, will be extinguished by operant-conditioning-employing competing products, there is also an obvious answer: We will make it a permanent obsession in our company that our beverage, as fast as practicable, will at all times be available everywhere throughout the world. After all, a competing product, if it is never tried, can’t act as a reward creating a conflicting habit. Every spouse knows that.”
After talking through operant conditioning, Munger turns to classical conditioning:
“We must next consider the Pavlovian [classical] conditioning we must also use. In Pavlovian conditioning, powerful effects come from mere association. The neural system of Pavlov’s dog causes it to salivate at the bell it can’t eat. And the brain of man yearns for the type of beverage held by the pretty woman he can’t have. And so, Glotz, we must use every sort of decent, honorable Pavlovian conditioning we can think of. For as long as we are in business, our beverage and its promotion must be associated in consumer minds with all other things consumers like or admire.
Such extensive Pavlovian conditioning will cost a lot of money, particularly for advertising. We will spend big money as far ahead as we can imagine. But the money will be effectively spent. As we expand fast in our new beverage market, our competitors will face gross disadvantages of scale in buying advertising to create the Pavlovian conditioning they need. And this outcome, along with other volume-creates-power-effects, should help us gain and hold at least fifty percent of the new market everywhere. Indeed, provided buyers are scattered, our highest volumes will give us very extreme cost advantages in distribution.
Moreover, Pavlovian effects from mere association will help us choose the flavor, texture, and color of our new beverage. Considering Pavlovian effects, we will have wisely chosen the exotic and expensive-sounding name “Coca-Cola,” instead of a pedestrian name like “Glotz’s sugared, caffeinated water.” For similar Pavlovian reasons, it will be wise to have our beverage look pretty much like wine, instead of sugared water. And so we will artificially color our beverage if it comes out clear. And we will carbonate our water, making our product seem like champagne, or some other expensive beverage, while also making its flavor better and imitation harder to arrange for competing products. And, because we are going to attach so many expensive psychological effects to our flavor, that flavor should be different from any other standard flavor so that we maximize difficulties for competitors and give no accidental same-flavor benefit to any existing product.”
Having dealt with Pavlovian conditioning, Munger moves on to social proof:
“What else, from the psychology textbook, can help our new business? Well, there is that powerful ‘monkey-see, monkey-do’ aspect of human nature that psychologists often call ‘social proof.’ Social proof, imitative consumption triggered by mere sight of consumption, will not only help induce trial of our beverage. It will also bolster perceived rewards from consumption. We will always take this powerful social-proof factor into account as we design advertising and sales promotion and as we forego present profit to enhance present and future consumption. More than with most other products, increased selling power will come from each increase in sales.
We can now see, Glotz, that by combining (1) much Pavlovian conditioning, (2) powerful social-proof effects, and (3) wonderful-tasting, energy-giving, stimulating and desirably-cold beverage that causes much operant conditioning, we are going to get sales that speed up for a long time by reason of the huge mixture of factors we have chosen. Therefore, we are going to start something like an autocatalytic reaction in chemistry, precisely the sort of multi-factor-triggered lollapalooza effect we need.
The logistics and the distribution strategy of our business will be simple. There are only two practical ways to sell our beverage: (1) as a syrup to fountains and restaurants, and (2) as a complete carbonated-water product in containers. Wanting lollapalooza results, we will naturally do it both ways. And, wanting huge Pavlovian and social-proof effects we will always spend on advertising and sales promotion, per serving, over 40 percent of the fountain price for syrup needed to make the serving.
A few syrup-making plants can serve the world. However, to avoid needless shipping of mere space and water, we will need many bottling plants scattered over the world. We will maximize profits if (like early General Electric with light bulbs) we always set the first-sale price, either (1) for fountain syrup, or (2) for any container of our complete product. The best way to arrange this desirable profit-maximizing control is to make any independent bottler we need a subcontractor, not a vendee of syrup, and certainly not a vendee of syrup under a perpetual franchise specifying a syrup price frozen forever at its starting level.
Being unable to get a patent or copyright on our super important flavor, we will work obsessively to keep our formula secret. We will make a big hoopla over our secrecy, which will enhance Pavlovian effects. Eventually food-chemical engineering will advance so that our flavor can be copied with near exactitude. But, by that time, we will be so far ahead, with such strong trademarks and complete, “always available” worldwide distribution, that good flavor copying won’t bar us from our objective. Moreover, the advances in food chemistry that help competitors will almost surely be accompanied by technological advances that will help us, including refrigeration, better transportation, and, for dieters, ability to insert a sugar taste without inserting sugar’s calories. Also, there will be related beverage opportunities we will seize.
This brings us to a final reality check for our business plan. We will, once more, think in reverse like Jacobi. What must we avoid because we don’t want it? Four answers seem clear:
First, we must avoid the protective, cloying, stop-consumption effects of aftertaste that are a standard part of physiology, developed through Darwinian evolution to enhance the replication of man’s genes by forcing a generally helpful moderation on the gene carrier. To serve our ends, on hot days a consumer must be able to drink container after container of our product with almost no impediment from aftertaste. We will find a wonderful no-aftertaste flavor by trial and error and will thereby solve this problem.
Second, we must avoid ever losing even half of our powerful trademarked name. It will cost us mightily, for instance, if our sloppiness should ever allow sale of any other kind of “cola,” for instance, a “peppy cola.” If there is ever a “peppy cola,” we will be the proprietor of the brand.
Third, with so much success coming, we must avoid bad effects from envy, given a prominent place in the Ten Commandments because envy is so much a part of human nature. The best way to avoid envy, recognized by Aristotle, is to plainly deserve the success we get. We will be fanatic about product quality, quality of product presentation, and reasonableness of prices, considering the harmless pleasure it will provide.
Fourth, after our trademarked flavor dominates our new market, we must avoid making any huge and sudden change in our flavor. Even if a new flavor performs better in blind taste tests, changing to that new flavor would be a foolish thing to do. This follows because, under such conditions, our old flavor will be so entrenched in consumer preference by psychological effects that a big flavor change would do us little good. And it would do immense harm by triggering in consumers the standard deprival super-reaction syndrome that makes “take-aways” so hard to get in any type of negotiation and helps make most gamblers so irrational. Moreover, such a large flavor change would allow a competitor, by copying our old flavor, to take advantage of both (1) the hostile consumer super-reaction to deprival and (2) the huge love of our original flavor created by our previous work.
Well, that is my solution to my own problem of turning $2 million into $2 trillion, even after paying out billions of dollars in dividends. I think it would have won with Glotz in 1884 and should convince you more than you expected at the outset. After all, the correct strategies are clear after being related to elementary academic ideas brought into play by the helpful notions.”
During the rest of the piece, Munger discusses the parallels between his fictional business plan and Coca-Cola’s actual business (hint: they’re pretty much the same.) He then goes on to relate his story to the main purpose of the talk: our failure to use basic academic wisdom to make better decisions.
He chalks this up, in part, to a failure of academia to produce a useful synthesis of topics like psychology and behavioral economics. He thinks that academic departments are too narrowly focused, and the research of academics to circumscribed.
Is there bullshit to sniff out here?
If you scan the shelves at an airport bookstore, you’re likely to find lots of books that, like Munger’s talk, purport to unveil some of the key attributes of successful companies. If you’ve ever been tempted to pick up a copy of Think Like Zuck: The Five Business Secrets of Facebook’s Improbably Brilliant CEO Mark Zuckerberg you know what I mean.
Because this is a common trope in the business literature – and it’s one that we often swallow uncritically – I want to take a few paragraphs to instill in you a healthy dose of skepticism in any person that purports to unveil the hidden attributes of successful companies:
First, anything that attempts to reduce the success of a business to a few key principles misses out on the obscene complexity that underlies the growth of any kind of organization.
Second, it misses the fact that many (but not all) organizations are incentivized to hide the real story behind their growth in order to protect their image, their investors, their employees, or their (perceived or real) competitive advantages.
Third, these attributes are subject to interpretation via the halo effect: they are seen as good ONLY because the company is successful. Many times you’ll see a CEO characterized as a visionary perfectionist when the stock is up, and an micro-managing egoist when the stock is down.
Fourth, Munger’s talk is (knowingly) given with the benefit of hindsight. It’s easy to point to many of these things as sure signs of success – once the success has been achieved.
Fifth, the attributes you see are subject to selection bias: people generally only write books or give talks about successful companies. Just because a successful company has attribute A, doesn’t mean that there aren’t a thousand other companies with attribute A that went to the graveyard.
What we’re really looking for is evidence that a particular company attribute played a causational role in their success – rather than just merely being associated with that success.
This is incredibly difficult, if not impossible, to do.
In the case of Munger’s talk I’m going to err on the side of believing him for two reasons:
- He puts his money where his mouth is. His very long investment track record provides some demonstration that his framework works at picking companies.
- He doesn’t claim universal applicability. His goal isn’t to give you a foolproof way of predicting company success – it’s to give you a framework, based in basic ideas, to help you think about that success.
So assuming we trust Munger, the next question we have to ask ourselves is: can we use what he’s saying?
Is all of this useful?
Clearly, if you’re running a big company this kind of framework could help you make better decisions. For example, had the executives at Coke who decided to introduce “New Coke” understood conditioning better they might have scrapped the plan before it became a disaster.
Similarly, if you’re an institutional investor evaluating a large consumer business like Coke he provides you an interesting framework to think about.
I think the argument can also be made that it provides a good framework for early-stage technology investors to think about – one that agrees with the startup-focused investors like Paul Graham, Peter Thiel, and others. (I think it’s always interesting when people who come from different backgrounds and work on different problems come to the similar conclusions about something, it usually means that there’s some truth to what they’re saying.)
Applying Munger’s framework to technology investing
If I had to summarize Munger’s advice in a few sentences (with the benefit of reading lots of other articles from him) it would be something like the following:
In order to get large (lollapalooza) effects like rapid growth you need to harness lots of different types of elementary forces. The forces to focus on create what we call positive feedback loops: they’re self-reinforcing. A causes B, B causes more A, which causes more B.
The forces of this type that Munger cites are psychological: operant conditioning and classical conditioning. All companies have to harness these kinds of psychological forces to grow. But there are other ones to look for as well:
- Economies of scale: the larger you are, the cheaper it is to produce your product, the more products you sell, the larger you get
- Network effects: the larger the network becomes, the more valuable the network is, the larger the network gets
- Word of mouth: the more of your product you sell, the more people talk about you, the more of your product you sell
- Big data effects: the more data a search engine has the, the better search results it can return, the more data it gets
- Incumbent advantages: the more large customers you have, the easier it gets to sign large customers, the more large customers you get
Finding companies that harness these effects is important for technology investors because the venture investment model is predicated upon huge returns from companies that dominate large winner-take-all markets.
And how do you get a winner-take all market?
One company has to be able to build an ever-increasing advantage against its competitors. It needs to be able to achieve high enough velocity to escape the gravity of market competition.
But how do you build this kind of ever-increasing lead?
You effectively harness the self-reinforcing forces we’ve been discussing: conditioning, economies of scale, network effects, word of mouth, big data effects, and others.
But what if you’re not an investor. What if you’re thinking of starting your own company? Can you use these ideas to come up with a startup?
Is this generative?
The first question to ask about his framework is this: is it generative?
By this I mean, will it help me generate new ideas for businesses to start. The answer to this question is clearly: no.
Thinking to yourself, “What companies can I start that will have self-reinforcing feedback loops?” doesn’t make your brain generate new ideas. As always, the best way to generate these ideas is through experience.
Paul Graham writes, “The way to get startup ideas is not to try to think of startup ideas. It’s to look for problems, preferably problems you have yourself.”
Ok, so Munger’s framework isn’t generative. The next question we have to ask ourselves is: is it diagnostic? In other words, assuming that Munger has identified some key causational elements of successful companies, how valuable is it for helping us diagnose companies at the idea stage?
The answer to this question is: if you’re looking to build a billion dollar company, it’s at best a marginally helpful guide. And the fact that it’s not incredibly helpful isn’t really Munger’s fault. There’s just no framework of elements out there that would allow us to perfectly predict how well our ideas are going to turn out.
There are lots of reasons for this. Here are a couple:
- Success is stochastic not deterministic
- Execution is more important than mere idea
- Your initial idea of what you’re building is often much different than what you actually build
Because what you actually build is often much different than what you think you’re building at the beginning, exact analysis of this kind is difficult to do. At best, what it can help you with is a general “sniff” test:
In general, does my vision for this product seem like it has the potential to harness some of these forces?
If the answer is yes then it’s time to get on to the next step and build the damn thing.
–
Works Cited:
Poor Charlie’s Almanack: The Wit and Wisdom of Charles T. Munger, Expanded Third Edition, Charlie Munger
Beyond Freedom and Dignity, B.F. Skinner
19 Jan 2015, 4:45am | 2 comments
The Inverted Pyramid: What Bertrand Russell Can Teach Us About The Limits of Logic

“To refute the solipsist…all that you have to do is take him out and throw a rock at his head: if he ducks he’s a liar. His logic may be airtight but his argument, far from revealing the delusions of the living experience, only exposes the limitations of logic.” – Edward Abbey
Something in Betrand Russell’s a History of Western Philosophy caught my eye recently. At first I noticed it because it’s basically Russell badly dissing another philosopher. But after I thought about it more I realized his point is really relevant to the way we think about the world and the way we make decisions.
In the passage that I’ll quote Russell wants to outline the differences between analytic and continental philosophy.
It’s difficult to define the exact differences between the two schools (they’re both terms that encompasses lots of different philosophers and world-views) but, roughly, analytic philosophy tends to try to break down philosophical problems into tiny pieces (like the definitions of words) and take a careful and considered look at each of the pieces and their relation to one another. Continental philosophy, on the other hand, is a bit more literary – it’s less concerned with the definitions of words and more concerned with broad synthesis.[^1]
Here’s how Lord Russell talks about the distinction:
“There is first of all a difference of method. [Analytic] philosophy is more detailed and piecemeal than that of the Continent; when it allows itself some general principle, it sets to work to prove it inductively by examining its various applications.”
By this he means that analytic philosophers don’t generally talk about broad, general principles. Instead, they like to build up their world-view in a more piecemeal fashion – considering one little question at a time. And when they do accept some general principle as true, they do so only when they can prove it by considering lots of empirical evidence in favor of the fact that it is true. They try not to make any large logical leaps that aren’t backed by experience.
By contrast, he says, Continental philosophers prefer deduction from first principles. As an example he talks about Gottfried Leibniz – the man who invented calculus[^2].
He chooses to examine how Leibniz argues for monadology – which is a theory of the nature of matter. The basic gist is that matter is made up of infinitely many “monads” – somewhat similar to geometrical points in that, by themselves, they don’t have “extension” or mass but when you get a lot of them together you can get a substance like wood or metal or dirt.
Lord Russell writes:
“When Leibniz wants to establish his monadology, he argues, roughly as follows: Whatever is complex must be composed of simple parts; what is simple cannot be extended[^3]; therefore everything is composed of parts having no extension. But what is extended is not matter. Therefore the ultimate constituents of things are not material, and, if not material, then mental. Consequently a table is really a colony of souls.”
Whoa! What just happened here? It seems like we went from some very simple basic propositions to an outlandish conclusion: “A table is really a colony of souls.”[^4]
How did that happen? Russell answers:
“The difference of method, here, may be characterized as follows: In Locke or Hume [both of whom are analytic philosophers], a comparatively modest conclusion is drawn from a broad survey of many facts, whereas in Leibniz a vast edifice of deduction is pyramided upon a pin-point of logical principle. In Leibniz, if the principle is completely true and the deductions are entirely valid, all is well; but the structure is unstable, and the slightest flaw anywhere brings it down to ruins. In Locke or Hume, on the contrary, the base of the pyramid is on the solid ground of observed fact, and the pyramid tapers upward, not downard; consequently the equilibrium is stable, and a flaw here or there can be rectified without total disaster.”
Russell’s problem with Continental philosophers is that they start with an axiomatic principle – something like “Whatever is complex must be composed of simple parts” – and they use it to deduct the rest of their worldview.
This is actually a valid method of figuring things out. For example, Euclid’s entire system of geometry is deducted from a few axiomatic principles. Pretty much any mathematical system works like this.
But what Russell is saying is that this system of thinking, while incredibly powerful, is also incredibly brittle.
This is generally not bad when you’re dealing with something like math because it doesn’t have to comport with experience – the axioms are true because we say they are. But when you’re reasoning about the real world it becomes a huge problem: it’s often impossible to tell if your axioms are correct. And equally difficult to know whether each of your deductions are valid.
And, if you’re reasoning in this way, if your starting axioms are wrong, or any of your deductions are invalid, all of your conclusions are totally wrong. It’s not robust to error at all. It’s a system of thought built like an upside down pyramid – the whole thing rests on one single point of balance.
Russell argues that a better way to do philosophy (or figure things out about the world in general) is to construct your pyramid right-side up. Start with known, observed facts about the world and construct your argument based on those. This will allow you to build a base of thought with strong foundations; one that’s much more robust to small errors than a purely deductive system of thought because it won’t come crashing down if one little piece is wrong.
There’s a common expression among programmers that goes, “Garbage in, garbage out.” And this is exactly how logic works. It’s a powerful tool that’s only as good as the person that uses it. And when we’re reasoning about things in the real world we want our system of thought to be like a right-side up pyramid – logic based on a robust foundation of experience – rather than a long chain of deduction that’s vulnerable to error and easy to tip over.
[^1]: If this still seems hopelessly unclear that’s because it is. To actually understand the differences you need to read some of the philosophers in question.
[^2]: he and Newton both independently came up with it around the same time
[^3]: Again this means, roughly, that it doesn’t have mass
[^4]: There’s a question about whether Bertie is really being fair to Leibniz here, but we’ll let it slide to hammer home the point.
31 Dec 2014, 5:09am | 2 comments
Writing and Running: Haruki Murakami

I’ve never read one of Murakami’s novels, but I recently picked up his memoir What I Talk About When I Talk About Running. I just finished Stephen King’s On Writing, so when I spotted it in a bookstore it seemed like a logical thing to read next.
Murakami’s prose is simple and his attitude is unassuming. Basically the entire book is spent talking about running (his main pastime aside from writing). The way he writes sets up a kind of hypnotic rhythm that he builds over the course of the book. Mostly he talks about marathons: training for marathons, running in marathons, competing in triathlons, etc. But every so often the book is also interspersed with these great nuggets about writing and life.
One parallel that Murakami draws between writing and running is that both act as a sort of alchemy for the events and emotions in his life. Both writing and running allow him to take what happens to him – events, emotions, feelings – and transmute them in to another, useful, form.
“When I’m criticized unjustly (from my viewpoint, at least), or when someone I’m sure will understand me doesn’t, I go running for a little longer than usual. By running longer it’s like I can physically exhaust that portion of my discontent. It also makes me realize again how weak I am, how limited my abilities are. I become aware, physically, of these low points. And one of the results of running a little farther than usual is that I become that much stronger. If I’m angry, I direct that anger toward myself. If I have a frustrating experience, I use that to improve myself. That’s the way I’ve always lived. I quietly absorb the things I’m able to, releasing them later, and in as changed a form as possible, as part of the story line in a novel.”
One thing that I noticed reading Murakami he has very deep, zen-like thoughts on the nature of the mind and the meaning of life, but he says them so matter-of-factly that you might miss them:
“The thoughts that occur to me while I’m running are like clouds in the sky. Clouds of all different sizes. They come and they go, while the sky remains the same sky as always. The clouds are mere guests in the sky that pass away and vanish, leaving behind the sky. The sky both exists and doesn’t exist. It has substance and at the same time doesn’t. And we merely accept that vast expanse and drink it in.”
He talks a lot about things that are constantly changing in form: clouds, the sky, and the water in the river where he runs. And he uses it to place himself in the broader picture of the world:
“The surface of the water changes from day to day: the color, the shape of the waves, the speed of the current. Each season brings distinct changes to the plants and animals that surround the river. Clouds of all sizes show up and move on, and the surface of the river, lit by the sun, reflects these white shapes as they come and go, sometimes faithfully, sometimes distortedly…In the midst of this flow, I’m aware of myself as one tiny piece in the gigantic mosaic of nature. I’m just a replaceable natural phenomenon, like the water in the river that flows under the bridge to the sea.”
A lot of writers talk about pain as the engine behind the creative process. Someone like Dostoevsky comes to mind. Murakami is in this camp as well. Here he talks about emotional pain:
“As I’ve gotten older, though, I’ve gradually come to the realization that this kind of pain and hurt is a necessary part of life. If you think about it, it’s precisely because people are different from others that they’re able to create their own independent selves. Take me as an example. It’s precisely my ability to detect some aspects of a scene that other people can’t, to feel differently than others and choose words that differ from theirs, that’s allowed me to write stories that are mine alone. And because of this we have the extraordinary situation in which quite a few people read what I’ve written. So the fact that I’m me and no one else is one of my greatest assets. Emotional hurt is the price a person has to pay in order to be independent…”
Aside from just emotional pain, Murakami also talks about physical pain, which is a key part of his routine as a serious marathon runner.
“Of course it was painful, and there were times when, emotionally, I just wanted to chuck it all. But pain seems to be a precondition for this kind of sport. If pain weren’t involved, who in the world would ever go to the trouble of taking part in sports like the triathlon or the marathon, which demand such an investment of time and energy? It’s precisely because of the pain, precisely because we want to overcome that pain, that we can get the feeling, through this process, of really being alive…Your quality of experience is based not on standards such as time or ranking, but on finally awakening to an awareness of the fluidity within action itself. If things go well, that is.”
By the end of the book, he’s sort of established the rhythm of his life for us: he writes, he trains for marathons, he runs marathons. Rinse and repeat. He’s consistently doing things, but not always making visible progress.
He likens it to pouring water in to an old pan with a hole at the bottom: there’s always water running through it, but the pan never fills up. But the message he leaves us with, is that despite pouring tremendous effort in to these seemingly inefficient activities, it’s these very activities that have borne the most fruit in his life.
“Even if, seen from the outside, or from some higher vantage point, this sort of life looks pointless or futile, or even extremely inefficient, it doesn’t bother me. Maybe it’s some pointless act like, as I’ve said before, pouring water in to an old pan that has a hole in the bottom, but at least the effort you put into it remains. Whether it’s good for anything or not, cool or totally uncool, in the final analysis what’s most important is what you can’t see but can feel in your heart. To be able to grasp something of value, sometimes you have to perform seemingly inefficient acts. But even activities that appear fruitless don’t necessarily end up so. That’s the feeling I have, as someone who’s felt this, who’s experienced it.”
14 Dec 2014, 9:04pm | 8 comments
Bertrand Russell and Will Durant on Philosophy, Science and Religion

I majored in philosophy in college, but it can still be difficult to define exactly what it encompasses and why it’s a unique way of looking at the world.
What does it mean? How is philosophical thinking different from scientific thinking? How is it different from religious thinking? Is philosophy irrelevant in the face of our ever-expanding scientific knowledge of the world?
I recently picked up Bertrand Russell’s classic tome The History of Western Philosophy and came across this excellent discussion of the word in its introduction:
Philosophy, as I shall understand the word, is something intermediate between theology and science. Like theology, it consists of speculations on matters as to which definite knowledge has, so far, been unascertainable; but like science, it appeals to human reason rather than to authority, whether that of tradition or that of revelation.
All definite knowledge – so I should contend – belongs to science; all dogmas as to what surpasses definite knowledge belongs to theology. But between theology and science there is a No Man’s Land, exposed to attack from both sides, and this No Man’s Land is philosophy. Almost all the questions of most interest to speculative minds are such as science cannot answer, and the confident answers of theologians no longer seem so convincing as they did in former centuries.
He goes on to list a few of the kinds of questions that philosophy considers:
Is the world divided into mind and matter, and, if so, what is mind and what is matter? Is mind subject to matter, or is it possessed of independent powers? Has the universe any unity or purpose? Is it evolving towards some goal? Are there really laws of nature, or do we believe in them only because of our innate love of order? Is man what he seems to the astronomer, a tiny lump of impure carbon and water impotently crawling on a small and unimportant planet? Or is he what he appears to Hamlet? Is he perhaps both at once? Is there a way of living that is noble and another that is base, or are all ways of living merely futile? Must the good be eternal in order to deserve to be valued, or it is it worth seeking even if the universe is inexorably moving towards death? Is there such a thing as wisdom, or is what seems such merely the ultimate refinement of folly?
To such questions no answer can be found in the laboratory. Theologies have professed to give answers, all too definite; but their very definiteness causes modern minds to view them with suspicion. The studying of these questions, if not the answering of them, is the business of philosophy.
Philosophy is tasked with answering “unanswerable” questions without resorting to dogma and revealed truth. Does it really achieve that? Many times, it seems like a lot of philosophy is just concerned with debating useless stuff.
Consider the thoughts of historian Will Durant:
Some ungentle reader will check us here by informing us that philosophy is as useless as chess, as obscure as ignorance, and as stagnant as content. “There is nothing so absurd,” said Cicero, “but that it may be found in the books of the philosophers.”
Doubtless some philosophers have had all sorts of wisdom except common sense; and many a philosophic flight has been due to the elevating power of thin air. Let us resolve, on this voyage of ours, to put in only at the ports of light, to keep out of the muddy streams of metaphysics and the “many-sounding seas” of theological dispute.
But is philosophy stagnant? Science seems always to advance, while philosophy seems always to lose ground. Yet this is only because philosophy accepts the hard and hazardous task of dealing with problems not yet open to the methods of science —problems like good and evil, beauty and ugliness, order and freedom, life and death; so soon as a field of inquiry yields knowledge susceptible of exact formulation it is called science.
Every science begins as philosophy and ends as art; it arises in hypothesis and flows into achievement. Philosophy is a hypothetical interpretation of the unknown (as in metaphysics), or of the inexactly known (as in ethics or political philosophy); it is the front trench in the siege of truth. Science is the captured territory; and behind it are those secure regions in which knowledge and art build our imperfect and marvelous world….
Science tells us how to heal and how to kill; it reduces the death rate in retail and then kills us wholesale in war; but only wisdom—desire coordinated in the light of all experience— can tell us when to heal and when to kill. To observe processes and to construct means is science; to criticize and coordinate ends is philosophy: and because in these days our means and instruments have multiplied beyond our interpretation and synthesis of ideals and ends, our life is full of sound and fury, signifying nothing. For a fact is nothing except in relation to desire; it is not complete except in relation to a purpose and a whole. Science without philosophy, facts without perspective and valuation, cannot save us from havoc and despair. Science gives us knowledge, but only philosophy can give us wisdom.
Both Russell’s The History of Western Philosophy and Durant’s The Story of Philosophy are excellent introductions to philosophical thinking.
Over the next few months I’m going to be experimenting with posting excerpts from books I read in this space (like this one) instead of just long essays. Ideally this will allow me write more frequently in between the times when I publish more personal long-form pieces.
8 Nov 2014, 4:10am | 2 comments
Latent serendipity
When I was a kid I liked to dress up in the stories of successful people.
I read about how Bill Gates used to rock in his chair when he was thinking, and for a few months after that I made sure to rock back and forth whenever I was programming. I read a book about Stephen Hawking that described how Oxford graduate students would buy huge sketchbooks to scribble physics formulas in, and so I went out and bought a huge sketchbook to carry around with me.
We all do this. We read little snippets of people’s lives in long magazine exposés, or see adaptations of their adventures in 2-hour summer biopics, and we take their personality traits and try them on like a pair of new shoes. Then we look at ourselves in the mirror of our minds and ask: “Does this fit? Do I do that too?”
When it’s something like rocking back and forth in our chair we can usually fudge it and say, “Yeah, I do that.” Sometimes we really do end up doing those things for a couple of weeks. Something in our brains tells us if we’re similar to these people we’ll be more likely to share in their success.
But sometimes, trying on these stories doesn’t work at all. There’s a special class of stories that make our minds come up blank.
You hear a singer say, “Well, my parents always played Aretha Franklin at home so she was a big influence for me.” Or an entrepreneur say, “Well, I noticed early on that customer service was the biggest part of running a successful business, and so that’s why our vision is to help companies do better support.”
It’s like successful people have these little insightful anecdotes that they can use to explain their lives. Things like, “This has always been important to me.” Or, “I noticed this from a young age.” Or, “I’ve always been really interested in this.” These anecdotes, these calcified bits of personal history, carry a certain kind of inevitability about them. Like they were always important, and clearly pre-destined to have a huge impact on the life of the person telling them.
When we hear these things, we think to ourselves, “What did I notice early on that I can use to start my business?” or “What did my parents do that’s going to influence my future success?”
Usually, we don’t have an answer. Our brains say, “Your parents never listened to Aretha Franklin.” Or, “You never noticed that customer service was important when you were a kid.” There’s nothing obvious about our daily lives that will inevitably lead to our future success.
Why is is this? Why do we feel like we don’t have this special kind of story to tell? Why can’t we talk about these obvious parts of our lives that will inevitably lead to our success?
And, if we don’t have them, how did these successful people get them? Is it causational? Are they successful because they’ve always known what was “unique” about their experiences that they could apply to their lives? Or is something else going on? Continue Reading
Recent Posts